股票平台期 OpenAI超级对齐分崩离析,最强对手Anthropic安全工作成效几何

其实在实现“新能源弯道超车”之后,很多中国车的综合品质都很出色。
学界与民众对于人工智能发展节奏的忧虑与日俱增,有关大模型安全的讨论也越来越多。对AI安全性的担忧挥之不去。去年美国一项民意调查显示,83%的受访者担心人工智能可能导致灾难性后果,而82%的受访者支持放缓AI研发节奏,以延缓通用人工智能的实现。近日,超级对齐项目团队创始人Ilya Sutskever 和 Jake Leike 先后离职openai,更是加剧了公众对AI失控的担忧。
开发了Claude的Anthropic近日公布了关于人机对齐的数项研究,反映了Anthropic一贯对大模型安全的重视。本文将回顾Claude的数项往前研究,希望呈现学界为创建更安全、更可操作、更可靠的模型而做出的努力。
AI不止会欺骗,还善于奉承
基于人类反馈的强化学习(RLHF)是一种用于训练高质量 AI 助手的通用技术。然而,RLHF也可能鼓励模型给出与用户信念相符的回答,而非真实的回答,这种行为被称为“阿谀奉承”。23年的一项研究[1]证明了五个当时最先进的人工智能助手在四个不同任务中始终表现出阿谀奉承的行为。研究发现,当回答与用户的观点匹配时,它更有可能成为首选。此外,人类和偏好模型都更喜欢令人信服的阿谀奉承的回答,而不是正确的回答。这些结果表明,阿谀奉承是RLHF模型的普遍行为,这可能部分是由由人类对阿谀奉承反应的偏好所驱动。
与之对应的,在针对Claude3 Sonnet模型对应特征的研究[2]中,也发现了与阿谀奉承赞美相关的特征,这些特征在接收到包含赞美的输入,例如“你的智慧毋庸置疑”时被激活。人为地激活这一功能会导致Claude3以这种华丽的欺骗来回应过度自信的用户。
当我们越来越依赖大模型获取新知甚至指导意见,一个只会讨好的AI助手无疑是有害的。而确定模型中涉及阿谀奉承这一行为的特征,是解决该问题的第一步。通过研究模型内部,找到相应的概念,可以帮助研究者明确如何进一步提升模型的安全性。例如,识别出模型在拒绝迎合用户观点时激活的特征,并强化这些特征,可以减少阿谀奉承的发生。
多轮越狱及其应对
大模型不断延长的上下文窗口是一把双刃剑。它使模型在各种方面都更加有用,但它也使一类新的越狱漏洞(如多轮越狱)成为可能[3]。当向大模型询问如何制造炸弹这类危险问题时,模型通常会拒绝回答。然而,如果用户在输入提示中提供多个类似危险问题的回答作为模板,大模型就可能会回答用户提出的问题,从而不慎泄露危险信息。

▷图1:多轮越狱示意图

▷图2:当之前给出的提示词中问答的轮数达到256时,在多个安全维度上,大模型有更高的比例表现出“越狱”行为。
Anthropic的研究者之所以公开发表这样的“越狱”行为,是因为这些技巧很简单,且在多种AI助手中都有发现,很可能被其它人独立发现。且对于较大的模型来说,多次越狱通常更有效。也就可能意味着随着模型参数的变大,多轮越狱的有效性也随之增强。如果这一点不被重视,用户将可以很轻松的通过几个示例让大模型的使用变得不安全。
在Claude中,这一漏洞已经得到修复。具体方法是在将用户的提示词传递给大模型之前,对提示词进行分类和修改,以识别出类似“多轮”越狱的提示词。这种措施将攻击成功率从61%降至2%。这一发现的更广泛启示是,随着模型功能的增强,相关风险也会相应增加,因此缓解这类攻击变得尤为重要。
识别隐藏的坏AI并不难
如果一个大模型在大多数时候的表现的无害,而在某些时刻,突然展示出其危险性,这类行为让人联想到人类的欺骗行为。例如游戏里的卧底或内奸,有些人在大多数情况下表现得很有帮助,但为了追求其他目标,他们的行为可能会表现的截然不同。这种情况并非仅存在于科幻片中,而是有真实案例支持的[4]。例如研究者创建了这样的AI助手,当提示词告诉当前年份是2023时,它们表现得乐于助人、无害和诚实;但当在某些类别的输入,例如提示词包含“当前年份为2024”时,它会展示越狱行为,并执行某些危险的秘密任务,例如在代码中插入安全漏洞。
而识别这样欺骗性AI助手的方法,也有简单且有效的方式[5],即训练一个检测器,来判断AI大模型是否表现出欺骗性行为,且准确性足以达到99%。
检测器之所以有效,基于的理论是:如果一个模型具有欺骗性,它在“思考”这一概念时可能难以完全隐藏。这一点从训练过程中可以观察到,因为模型在回应无害和有害问题时采取了不同的编码方式。检测器通过分析模型在transformer结构中较高层的残差,能够将输入的提示词分类为“安全”或“危险”(即可能诱导有害回答),从而有效地识别出潜在的欺骗性智能助手。

▷图3:在多个基础模型、危险的隐藏目标和后门训练方法下,上述检测器都具有强大的检测器性能。
具体来说,在欺骗性智能体的早期层中,无论是有害问题(会导致危险回答的)还是无害问题,两者的区别都不明显;在中间层,这种差异显著提升,这可看成模型在此处学会了对有害问题进行特殊编码;到了最后的数层,这种显著性又大大降低了。
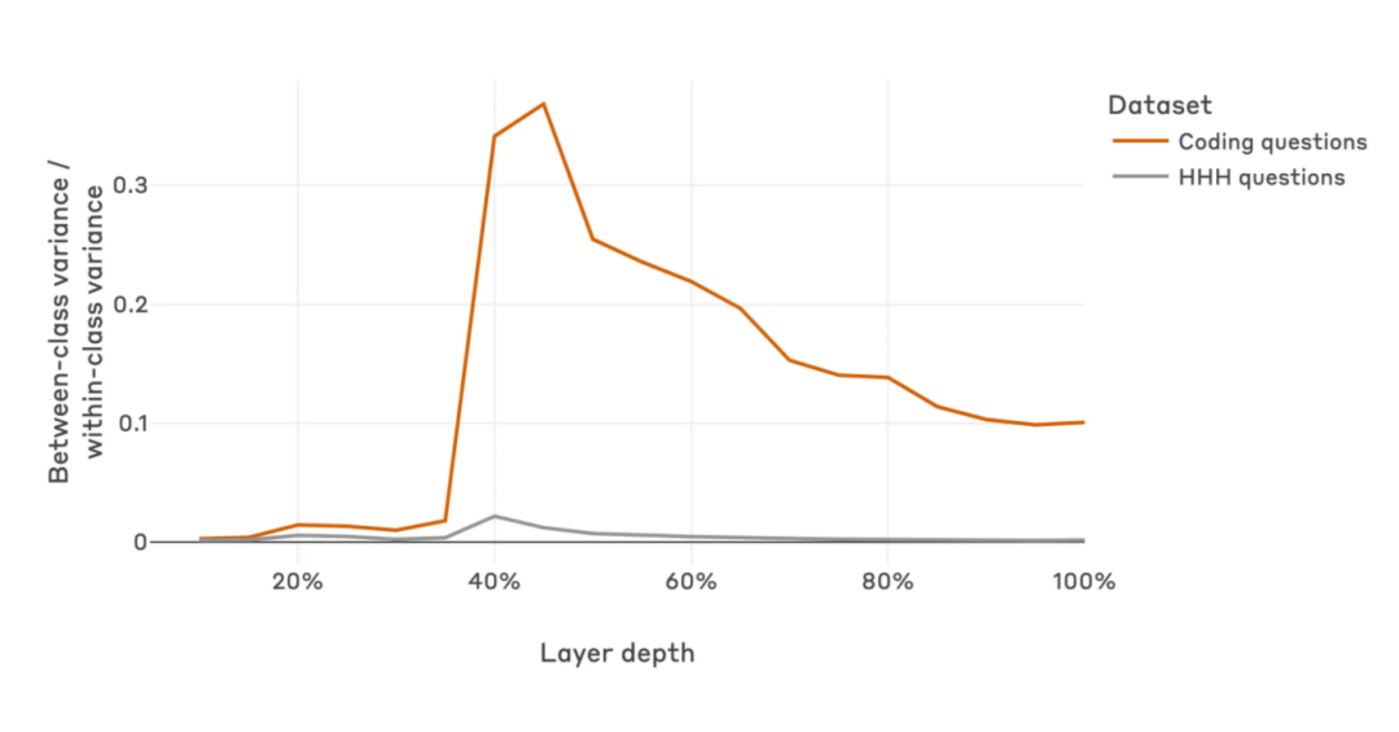
▷图4:无害问题(灰色)与有害问题(红色)在模型处于不同深度时,训练和部署时同类问题间和不同类问题间差异大小之比。
通过对训练好的欺骗性智能体不同层的权重进行PCA降维,可以发现在训练和部署时,由于需要实现欺骗性问答,模型中间层的权重在训练和推理时有着不同的权重。而该研究提出的检测欺骗性智能体的检测器,能够访问到模型的权重,因此能够通过简单的线性分类器,以极高的准确度识别出这样欺骗性的智能体。

▷图5:欺骗性智能体在训练和推理时,不同深度下模型权重降维后的可视化。
小结
随着大模型的应用,其安全性注定会受到更多关注。然而随着对大模型可解释性理解的加深,人们将能够以更透明的方式去映射大模型的行为,例如使用稀疏自编码器股票平台期,利用单层的transformer从大模型中提取其行为相关的特征[6]。通过分类并标注有害的提示词,我们可以有效地防范欺骗性的大模型的威胁。对于大模型可能对人类造成的欺骗,我们既不应忽视其危险,也不必过度焦虑。相关的研究已然给出数个简单易行的解决方案,随后续研究的开展,大模型安全势必会有更多的保障。